AWS账号:什么是 Amazon Bedrock?免服务器一键调用 DeepSeek-R1 与 Claude 3.5 的终极神器

大模型技术日新月异。前脚刚被 Claude 3.5 系列极其惊艳的编程和逻辑能力震撼,后脚具有划时代意义的开源满血推理大模型 DeepSeek-R1 就火遍了全球。
对于开发者和企业团队来说,把这些顶尖模型接入到自己的业务系统中,痛点非常明显:
- 用开源模型(如 DeepSeek-R1): 需要自己买昂贵的 A100/H100 显卡服务器,还要折腾各种复杂的推理解构框架、算力扩容和高并发优化,运维成本高上天。
- 用商业 API(如 Anthropic 官方): 虽然免去了服务器的烦恼,但在国内面临网络不稳定、账单支付门槛高,以及核心数据安全(无法过内网合规审核)等现实大坑。
如果你也面临这些两难抉择,那么是时候了解一下这款托管神器了——Amazon Bedrock。
简单来说,Amazon Bedrock 是亚马逊云(AWS)推出的生成式 AI 完全托管服务。它最大的杀手锏就是:彻底免去服务器,只需一个统一的 API,就能一键调用包括 DeepSeek-R1 满血版、Claude 3.5 全家桶、Amazon Nova、Llama 3 等在内的全网最强模型阵容。
核心原理:Amazon Bedrock 的“无服务器”到底有多爽?
传统的云端模型部署(比如用 SageMaker 或是自建云服务器),本质上你租用的是“算力”。你需要根据并发量去猜自己该买多少台 GPU。
而 Amazon Bedrock 玩的是 Serverless(无服务器化) 的逻辑:
通过 Bedrock,你不再需要面对任何具体的 GPU 硬件。AWS 把这些顶级模型全部做成了全托管的后端公共池。
- 按需调用,按量计费: 你的业务系统发一个请求(比如一段代码优化提示词),Bedrock 吐出结果,AWS 根据你消耗的 Input/Output Token 收取几美分或千分之几美金。没有请求时,费用直接归零。
- 无限扩容: 不管你的 APP 今天是 10 个并发还是明天突然爆量到 10 万个并发,底层的算力弹性全部由 AWS 在后台用全球机房的庞大资源自动顶上,你不需要写一行自动扩容脚本。
- 统一的 API 格式: 换模型就像换皮肤。今天你用的是 Claude 3.5 Sonnet,明天你想换成 DeepSeek-R1 试试推理能力,只需要在代码里改一个 modelId 的字符串参数,整体业务架构和数据结构甚至连一个标点符号都不用改。
强强联手:DeepSeek-R1 与 Claude 3.5 在 Bedrock 上的绝佳表现
为什么说它是当下的终极神器?因为 Bedrock 把目前闭源最强的“工程/代码之王”和开源最强的“深度推理之王”放在了同一个屋檐下。
- DeepSeek-R1(满血版): Bedrock 官方直接托管了满血版的 DeepSeek-R1。它在数学、复杂逻辑、代码算法设计上表现极其惊人,且特有的“深度思考(Thinking Process)”会完整输出。在 Bedrock 上调用它,彻底告别了本地部署的显存爆掉(OOM)问题。
- Claude 3.5 全家桶(Sonnet / Haiku): 业内公认最懂开发者的语言模型。不管是 Artifacts 的前端生成、极其复杂的上下文理解,还是高效率的多步工作流自动化,Claude 3.5 都是目前企业级商业落地的首选。
在 Bedrock 上,你可以轻松实现两者的多模型路由编排(Router)。比如:简单的客服对话交给低成本、极速响应的 Claude 3.5 Haiku;遇到复杂的代码架构重构直接路由给 Claude 3.5 Sonnet;而遇到极其烧脑的算法逻辑或财务审计分析,则一键调用 DeepSeek-R1 让它“思考”出最优解。
实战起步:三步解锁你的 Bedrock 模型
很多团队以为接入 AWS 肯定有一套极其繁琐的过程,其实 Bedrock 的上手门槛极低。
第一步:开启模型访问权限(Model Access)
出于合规和全球各区域机房容量的考虑,新开通的 AWS 账号默认是不解锁第三方模型的。
- 登录你的 AWS 管理控制台,在顶部搜索栏输入 Amazon Bedrock。
- 进入 Bedrock 控制台后,滚动左侧菜单到最下方,找到 Model access(模型访问权限)。
- 点击页面右上角的 Manage model access(管理模型访问权限)。
- 在列表中勾选你需要的模型(如 Anthropic -> Claude 3.5 Sonnet 以及 DeepSeek -> DeepSeek-R1)。
- 点击确定提交,通常几分钟内,这些模型的权限状态就会变成绿色的 Granted(已授权)。
第二步:利用控制台 Playground 零代码测试
在写代码之前,你可以先在控制台里试试它们的深浅:
- 在左侧菜单点击 Playgrounds -> Chat(聊天操纵台)。
- 点击 Select model,选择刚才解锁的 DeepSeek-R1。
- 直接输入你的烧脑难题。你会发现,得益于 AWS 庞大的基础设施,满血版 R1 的响应速度和稳定性表现堪称工业级。
第三步:直接用 Python 代码一键调用
当你想把它们集成到你的 Python 后端或者 Agent 框架中时,只需要用到 AWS 的官方 SDK boto3。来看一段极简的统一调用代码:
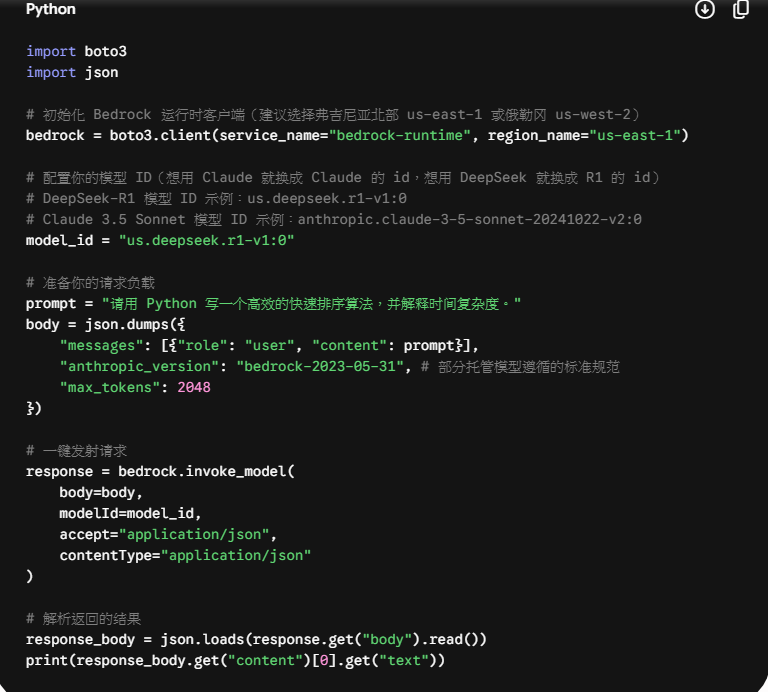
看,完全没有复杂的算力初始化,没有显卡驱动升级,仅仅用这一段不到 30 行的代码,你就把当今世上两头最顶级的“AI 猛兽”据为己用了。
核心安全屏障:为什么大企业更愿意在 Bedrock 上跑大模型?
对于企业、尤其是需要处理敏感业务、涉及海外合规(如 GDPR、HIPAA)的用户来说,数据安全是绝对不可触碰的红线。如果直接调公网第三方接口,数据被拿去二次训练的风险极大。
而 Amazon Bedrock 给出了企业级的终极数据保险箱机制:
- 绝对的数据隔离: 你的所有提示词(Prompt)、模型生成的回答以及通过 Bedrock 训练的任何微调数据,永远锁在你在 AWS 的专属 VPC(虚拟私有云)境内。
- 绝不用于公共训练: 亚马逊云官方白纸黑字承诺,你进出 Bedrock 的任何数据,绝不会被 AWS、Anthropic 或 DeepSeek 官方拿去作为底座模型的迭代训练材料。
- 企业内网直连(AWS PrivateLink): 你的业务服务器和 Bedrock 模型之间可以完全不走因特网公网,全部走 AWS 内部骨干网的内网专线通信,彻底绝断了数据在中途被截获的可能。
总结
Amazon Bedrock 彻底颠覆了大模型的日常工程范式。它打破了“闭源大模型买服务、开源大模型买显卡”的传统逻辑,将全网最优解做成了一种极其清爽的基础设施级公共自来水。
你再也不用关心硬件缺货、不用为高昂的显卡闲置费账单掉头发。通过 Bedrock 的无服务器一键调用,你可以把百分之百的精力,投入到设计更精妙的 Agent 业务流程和产品创新中去。
现在就去你的 AWS 控制台点开 Bedrock 吧,这绝对是你今年出海或者构建 AI 原生应用时,最不想错过的提效神兵。
