Azure微软云账单代支付:Azure Synapse Analytics现代化数据仓库极速上手教程

在如今的大数据时代,很多企业在做数据分析和报表时,经常会陷入一种极度尴尬的“便秘状态”:
公司跑了几年积累了几个 TB 甚至 PB 级的数据,全散落在不同的地方(业务数据库、日志文件、各种第三方 SaaS 平台)。产品经理或者运营总理想拉一个“跨季度、多维度”的用户画像分析报表,结果在传统的 SQL 数据库里点下“执行”,大半天过去了,系统还在疯狂转圈。好不容易等到了下午,不仅报表没跑出来,还因为这个天价查询把线上生产环境的数据库 CPU 直接顶满,导致前端 APP 瞬间卡死,被客户投诉得体无完肤。
这种传统的“烟囱式”或者“小作坊式”数据架构,在海量数据面前不堪一击。业务痛死、开发累死、运维吓死。
为了彻底降维打击这种海量数据查询慢、数据到处散落的痛点,微软云(Azure)掏出了它在数据分析领域的王牌终极武器——Azure Synapse Analytics(现代化数据仓库/分析服务)。
它的核心逻辑粗暴且优雅:它把传统的“企业级数据仓库(Data Warehouse)”和现代化的“大数据分析(Big Data Analytics)”强行揉在了一个完全托管的独立天幕空间里。 它底层依靠大规模并行处理(MPP)架构,能把原本需要跑几个小时的复杂巨型查询,拆分成几十个甚至上百个小任务,交给后端的计算集群同时去轰炸。你只需要写完一段标准的 SQL 语句,敲下回车,在海量数据面前,它依然能给你实现秒级响应。
今天我们拒绝任何官方说教和枯燥的理论参数,直接从真实的现代化大厂生产实践切入,手把手带你无痛揭开 Azure Synapse Analytics 的神秘面纱,10 分钟在云端搭建起一套属于你自己的极速大数据分析阵地。
第一阶段:深度拆解,Azure Synapse 的“多维宇宙模型”
在动手去点控制台之前,你必须在脑子里建立起 Azure Synapse 底层的物理世界模型。很多人进到它的控制台里会迷路,就是因为没搞懂它里面其实并存着三个完全不同的“平行宇宙算力”:
- 宇宙一:无服务器 SQL 池(Serverless SQL Pool,探索先锋): 这是最省钱、也最神奇的黑科技。它没有实体服务器,按你查询的数据量算钱(1 TB 大约 5 美元)。它的唯一任务,就是当你手里有一堆乱七八糟的 CSV、JSON 或 Parquet 文件躺在云端存储里时,你不用建任何表,直接用一段标准的 SQL 语句就能像查数据库一样去“穿透”查询这些文件。适合做突发性的数据探索。
- 宇宙二:专用 SQL 池(Dedicated SQL Pool,主力重骑兵): 这就是传统意义上的大厂企业级数据仓库(原名 Azure SQL DW)。它是按小时固定收钱的实体集群。它采用标准的 MPP(大规模并行处理)分布式架构,数据进来后会被打散分发到 60 个底层的存储单元里。当你需要跑公司核心的、几亿条数据的日常固定大报表时,这个重骑兵集群会全速运转,提供死死固定的秒级响应。
- 宇宙三:一体化数据集成(Synapse Pipelines,搬砖工): 你可以把它理解为内置在里面的 Azure Data Factory(ADF)。它不需要你写一行代码,纯靠拖拉拽,就能自动从你公司本地的自建机房、或者是外部的各种数据库里,把数据源源不断地自动“抽”到这个仓库里来。
大厂高明之处:这三个宇宙在同一个界面里完全打通,数据共享、算力隔离。这才是现代现代化数据中台的天花板。
第二阶段:实战演练——10 分钟平地起高楼,搭建现代化极速数仓
请确保你已经拥有了一个 Azure 账号,并且已经建好了一个基础的 Azure Data Lake Storage Gen2(数据湖存储) 用来存放原始文件。
步骤 1:开辟 Synapse 独立宇宙工作区(Workspace)
- 登录 Azure 门户网站(Portal)。
- 在上方搜索栏输入 “Azure Synapse Analytics”,点击进入核心控制台。
- 点击顶部的 “+ Create”:基本信息:选好你的资源组,给工作区起名叫 synapse-workspace-prod,地域选择离你最近的(如 East Asia 香港)。指定数据湖(Select Data Lake Storage Gen2):选中你提前建好的 Storage Account(存储账户),并指定一个容器(Container)起名叫 raw-data。注:这个容器将作为整个数仓的“大后方基地”,所有原始文件都会往这里扔。
- 输入你的管理员用户名和密码,连续点击下一步直到创建完成。
步骤 2:登录上帝视角工作台(Synapse Studio)
创建完成后(通常需要 2 分钟左右),点击进入该资源页面。
- 在正中央,你会看到一个极其醒目的亮蓝色大按钮:“Open Synapse Studio”。
- 毫不犹豫点它!页面会自动跳转到一个完全独立的、极具科幻感的数据世界工作台。大厂里所有的数据科学家、BI 工程师和网管,天天就是在这个界面里并肩作战。
第三阶段:实战演练二——用 Serverless SQL 一秒钟“穿透”查询海量原始文件
我们现在来模拟一个最真实的开发场景:公司的海外电商系统刚刚把上个月几千万条、好几个 GB 压缩过的全球用户订单交易日志(Parquet 格式或 CSV 格式),全量自动抛到了我们的 raw-data 数据湖容器里。
现在产品经理急着要看:“上个月在全球范围内,消费金额最高的前 10 名土豪用户是谁?”
按照以前的做法,你得建表、写代码写 ETL 把这几千万条数据导入数据库,折腾大半天。但在 Synapse 面前,我们用 Serverless SQL 玩一场极限闪电战。
- 在 Synapse Studio 界面左侧,点击 “Data”(数据) 图标。
- 切换到 “Linked”(已链接) 标签页,展开你的 Data Lake 存储账户,找到那个存放订单文件的文件夹。
- 见证黑科技的瞬间:在那个硕大的订单文件上点击右键,选中 “New SQL script” -> “Select TOP 100 rows”。
系统会自动为你生成一段奇迹般的 SQL 语句。我们把它稍微魔改一下,直接写出产品经理要的核心逻辑:
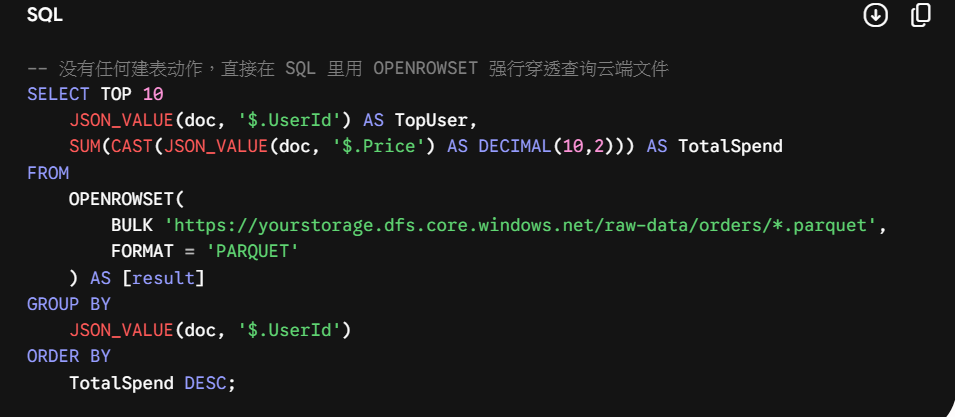
点击顶部的 “Run”(运行)。
后端的 Serverless 算力瞬间原地爆发,它不需要任何索引,直接在数据湖里疯狂横扫读取所有分散的文件。仅仅过了几秒钟,下方的 Results 窗口里便整整齐齐地跳出了那 10 个土豪用户的 ID 和消费总额。
拉过产品经理,把屏幕转给他看,全过程不费吹灰之力,这就是云原生现代化数仓的速度。
第四阶段:大厂级高并发架构下的避坑血泪史
这套全托管的大数据中台用起来爽快到飞起,它直接帮你抹平了底层分布式的全部复杂度。但要在真正严苛的商业大流量、高并发报表战场里稳定活下来,作为首席数据架构师,你在合拢电脑前,必须立刻下达行政命令去焊死以下两个隐形大坑:
1. 致命的“Serverless SQL 盲目乱扫”引发的财务惨剧
前面说过,Serverless SQL 极其方便,不需要开机,按查询的数据量算钱(每扫描 1 TB 收费大约 5 美元)。
- 灾难发生:如果你们公司有个初级开发或者运营,写了一条极不规范的查询语句(比如没有任何时间范围限制、直接使用 SELECT * 模糊匹配扫全盘),然后把这个查询塞进了一个每 5 分钟就自动触发一次的循环脚本里。由于它每次都会疯狂扫描几百个 GB 的原始日志,几天下来,这张 Serverless SQL 的扫描费账单能直接轻松烧掉几千美金,财务会直接提着刀来找你。
- 架构师标准免死金牌配置:物理限速锁:在 Synapse Studio 里面,点击进入 “Manage”(管理) -> “SQL pools”。点击控制 Serverless SQL 池的内置设置,强行配置“Daily/Weekly/Monthly data processed limits”(每日/每周/每月最大数据处理量限制)。比如设为每天最多只能扫 2 TB。一旦有垃圾代码或者死循环脚本触发超标,系统会一秒钟无情掐断查询并报错,死死守住公司的资金大盘。
2. 严禁在专用 SQL 池里疯狂使用“传统行级乱抖动”(Row-by-Row Updates)
当你开通了 Dedicated SQL Pool(专用 SQL 池) 用来做核心数仓时,你的代码习惯必须彻底从“小作坊”思维转变成“分布式”思维。
- 内幕曝光:传统关系型数据库(如 SQL Server / MySQL)里,我们经常写 UPDATE my_table SET status = 1 WHERE id = 123;。但在 Synapse 的分布式架构里,数据是被打散分发在 60 个存储节点里的。如果你在代码或者 ETL 流程里,疯狂用循环去跑这种单条记录的 Update 或 Insert,会导致底层的分布式协调大脑(Control Node)为了频繁锁表和网络同步而彻底脑死亡,速度反而比单机数据库还要慢上一百倍!
- 硬核加固规范:永远采用“大批量以全代修”的流派(Bulk Load)。如果需要更新数据,永远先用高配的 PolyBase 或者 COPY 命令,把几万条新数据一股脑、批量(Bulk)砸进一张临时分段表(Staging Table)里。然后用一条干净纯粹的、面向集合的语句进行批量覆盖或合并。顺应分布式集群的胃口去写代码,它才会给你回报真正的秒级响应。
总结
利用 Azure Synapse Analytics 快速架设企业级现代化数据仓库,核心的工业级精髓其实简化为十六个字:算力分流、穿透探索、总量锁死、大批吞吐。
你彻底告别了过去到处求爷爷告奶奶去求不同系统导数据、提心吊胆怕跑大报表卡死线上系统、天天为了虚拟机内存溢出掉头发的原始苦海。把所有最沉重的海量算力压力,完全托管给微软百亿美金打造的分布式 MPP 云原生大脑。坐在电脑前,优雅地拉开一张精美的数据大盘,淡定地看着几亿条数据在眨眼间驯服听话,这才是现代现代化数据时代架构师最优雅的变现姿势。
