AWS亚马逊云合作伙伴:揭秘AWS CloudFront高级玩法:利用Edge@Lambda在边缘节点实现定制化方向

玩过跨境电商、海外独立站或大流量海外 App 的朋友,对 Amazon CloudFront(AWS 的全球 CDN) 肯定不陌生。平时大家用它,大多是当个大号的“静态缓存盾牌”来使:缓存个图片、加速个视频、挡挡恶意的 DDoS 攻击。
但如果你对 CloudFront 的理解只停留在“静态缓存”,那就真的暴殄天物了。
今天聊点高级的硬核玩法:Lambda@Edge。简单来说,它能让你把自定义的代码(Node.js 或 Python),直接“发射”到 AWS 全球成百上千个 CDN 边缘节点上。请求还没到你的源站服务器,在离用户最近的那个 CDN 节点上,代码就已经执行完毕并完成了定制化分流、重定向或内容修改。
这不仅能帮你的源站服务器分担 90% 的业务逻辑压力,还能把全球用户的响应延迟压缩到极致。咱们不废话,直接开整。
第一阶段:看懂 Lambda@Edge 的 4 种触发时机
要在边缘节点玩出花样,你必须先死死记住 CloudFront 完整的请求链条。一个请求从用户手机发出到拿到数据,总共会经过 4 个关卡。你可以把你的 Lambda 代码精确地插在任意一个关卡上:
- Viewer Request(观众请求):用户刚把请求发送到 CDN 节点。此时 CDN 还没检查自己有没有缓存,代码插在这里最适合做:A/B 测试分流、封禁特定恶意 IP、重定向老旧 URL。
- Origin Request(源站请求):CDN 节点检查了,发现没有缓存,准备硬着头皮去你的源站服务器拿数据。代码插在这里适合做:动态修改回源路径、根据用户设备(手机/电脑)把请求转给不同的源站。
- Origin Response(源站响应):源站服务器把数据吐给 CDN 节点了,准备存进缓存。代码插在这里适合做:清洗或追加特定的 HTTP 响应头、安全策略注入。
- Viewer Response(观众响应):CDN 节点准备把数据正式回传给用户的浏览器。代码插在这里适合做:动态注入个性化、不适合缓存的零碎数据。
第二阶段:实战演练 —— 利用边缘脚本实现智能 A/B 测试分流
光说不练假把式。我们直接来还原一个企业级的高级场景:公司前端发版了新功能,需要做 A/B 测试。我们希望全球用户在访问 [ht tps://yourcompany.com/index.html]
https://yourcompany.com/index.html) 时:
- 50% 的用户留在老页面。
- 50% 的用户悄悄被引流到新页面 index_v2.html。
- 硬性要求:全过程用户浏览器地址栏的 URL 不能变,且不能让源站服务器参与判断,全在 CDN 边缘搞定。
这个需求,最适合把 Lambda 焊在 Viewer Request(观众请求) 关卡。
第一步:在 us-east-1 地域编写 Lambda 函数
铁律警告:不管你的业务在全球哪个角落,Lambda@Edge 必须在 “弗吉尼亚北部(us-east-1)” 地域创建,否则无法部署到全球 CDN 节点。
- 登录 AWS 控制台,切换到 us-east-1,新建一个 Lambda 函数。
- 运行语言选择 Node.js(边缘函数对执行速度要求极高,Node.js 是首选)。
- 权限方面,必须在执行角色里允许 edgelambda.amazonaws.com 服务主体调用该函数。
- 写入以下核心魔改逻辑代码:
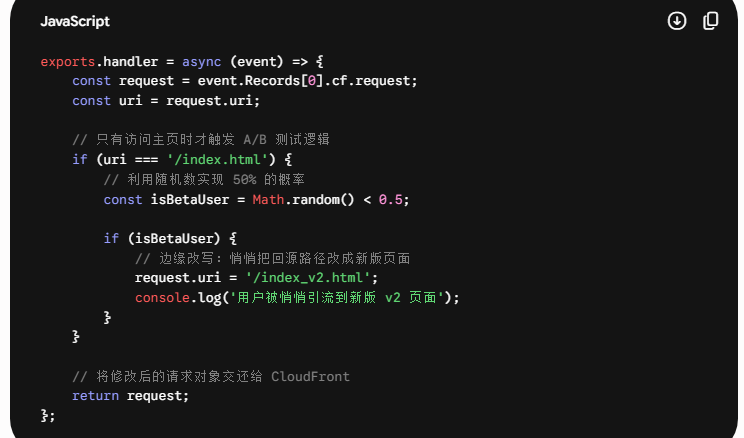
点击 Deploy 保存。
第三阶段:将代码“发射”到全球边缘节点
代码写完了,怎么让它去全球的 CDN 节点上站岗?
- 在 Lambda 函数页面的右上角,点击 “Actions” -> “Deploy to Lambda@Edge”。
- 配置部署参数:Distribution:选择你现有的 CloudFront 实例 ID。Cache Behavior:选择具体的缓存行为(比如默认的 * 或者是针对 /index.html)。CloudFront Event:毫不犹豫选择 Viewer Request。
- 勾选确认弹窗,点击部署。
此时,AWS 会在云端启动自动化分发程序,把你这段几十行的 Node.js 代码,在几分钟内复制、同步到全球几百个 CDN 边缘节点上。
第四阶段:测试验证与边缘玩法的避坑血泪史
部署完成后,你用世界各地的网络去疯狂刷新你的网站。你会发现,地址栏永远显示 index.html,但屏幕上却在老版和新版之间随机切换。源站服务器的日志里干干净净,它甚至不知道发生了 A/B 测试,全部压力被 CDN 节点在最前端化解了。
但在你兴奋地准备给所有业务都套上 Lambda@Edge 之前,必须先吃透这几个由于“边缘执行”带来的残酷限制,否则一不小心就会把整个 CDN 搞崩溃:
1. 严格的“身板”与时间限制
边缘节点为了追求极致的响应速度,留给代码的资源非常吝啬:
- 如果你在 Viewer Request / Response 阶段加代码,你的代码包大小不能超过 1MB,执行超时时间不能超过 5 秒,能用的内存只有 128MB。
- 别指望在边缘节点写个复杂的深度学习模型或者去连接传统的远程高延迟数据库。边缘代码的原则是:能多短就多短,能多快就多快。
2. 杜绝直接连生产数据库(会拖死网速)
如果你的 Lambda@Edge 在每次用户请求时,都要跨国连接一个位于北京或者俄勒冈的物理 MySQL 数据库来查用户资料,那么 CDN 带来的加速优势会被高昂的网络跨国延迟全部抹杀。
- 正确做法:如果必须要读写数据,请配合使用 Amazon DynamoDB Global Tables(全球分布式 NoSQL 数据库),或者利用功能受限但速度更快的 CloudFront KeyValueStore (KVS)。
3. 注意看住你的钱包
Lambda@Edge 是按“请求次数”和“执行时间(毫秒级)”算钱的。如果你的网站每天有几亿的 PV 流量,每一笔流量都要触发一次复杂的 Viewer Request 脚本,那么月底的 Lambda 账单可能会让你肉疼。
- 省钱绝招:如果只是做简单的 HTTP 重定向、根据国家码改写路径、或者追加安全响应头(如 HSTS 防劫持),优先使用 CloudFront Functions。它是 Lambda@Edge 的低配轻量版,执行速度在亚毫秒级,成本只有 Lambda@Edge 的几分之一,且不需要在 us-east-1 绕圈部署。
总结
揭开高级玩法的面纱,Lambda@Edge 的本质就是把“计算能力前置”。通过把 A/B 测试、防盗链验签、移动端自适应重定向等逻辑从中心化的服务器剥离,放到全球分发的边缘节点上,你不仅获得了一个坚不可摧、无限弹性的前端防线,更用最低的架构成本换来了全球用户丝滑般的顺畅体验。
